Want to present couple of new T-SQL Logical Functions implemented in SQL Server 2012.
The first function is "CHOOSE". It simply chooses one value from a provided list.
Here are couple of examples:
SELECT CHOOSE(3, 'ab', 'cd', 'ef', 'gh');
SELECT CHOOSE(5, 0, 1, 2, 3, '4');
First query will return third value "ef" and the second query will return number "4".
That means you can use any data type in the list as far as all items are of the same type or types can be converted by SQL Server.
It is pretty easy. What about the limits?
Books Online do not mention any limits. The biggest number of items I was be able to test with was 4426. That depends also on size of items and on the first parameter, which value has to be chosen.
In some cases I've got following error:
Msg 8631, Level 17, State 1, Server Bla-Bla-Bla, Line 1
Internal error: Server stack limit has been reached. Please look for potentially deep nesting in your query, and try to simplify it.
Here are automated testing results for SQL Express 2014: In Research batch script I was be able to execute "CHOOSE" function with 4981 items and item size upper than 60 bytes each (probably goes higher, but I've stopped the test).
However, in manual mode it shows even better results: Up to 4985 Items with item size 64Kb !!!
I'd consider it as a pretty high limit with query size as big as 300 Mb.
The second function is "IIF" !!!
It was more than 20 years available in MSAccess version of SQL and I really missed it.
For those who do not know what it is: It is just a shorter version of "CASE" clause, which chooses between only two choices.
IIF has three parameters: First parameter is a logical statement, second parameter is a value, which will be returned when the first parameter is "True". In case the first parameter is "False", third parameter's valuse will be returned.
"IIF" looks more convenient than "CASE", but it is about 1.5% slower on SQL 2014 and about 2% slower on SQL 2012.
Just compare two queries below. They produce the same results by marking Even and Odd numbers:
SELECT TOP 10 message_id,
CASE message_id % 2 WHEN 0 THEN 'Even' ELSE 'Odd' END
FROM sys.messages;
SELECT TOP 10 message_id,
IIF(message_id % 2=0,'Even','Odd')
FROM sys.messages;
Unfortunately, do not think a lot of people will be using it because of it slowness.
Thursday, November 20, 2014
Wednesday, November 19, 2014
Dedicated Admin Connection (DAC) in SQL Express
I've tried to do some exercises on my local VM with SQL Server Express edition, required Dedicated Admin Connection (DAC).
Faced the problem that I can not actually do it. After a short research found very easy solution.
1. Run SQL Server Configuration Manager. You can use an icon from windows menu or if it is not available you might use the following (or modified for your system/version) command:
C:\Windows\SysWOW64\mmc.exe /32 C:\Windows\SysWOW64\SQLServerManager12.msc
2. In Configuration Manager locate your SQL Server instance and choose properties by right click on it.

3. In Properties, choose "Startup Parameters" tab:

4. In the box specify a trace flag: "-T7806" and press Add.
5. Then hit OK and restart SQL Server Service.
Another way to do the same thing is would be editing Windows registry by RegEdit.exe
You just have to add new key "SQLArgX" with "-T7806" in
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQLServer\Parameters
That should look something like this:

That also require SQL Server instance restart.
Also, in order to be able to establish DAC you have to enable it within your SQL Server configuration:
sp_configure 'show advanced options', 1;
GO
RECONFIGURE
GO
sp_configure 'remote admin connections', 1;
GO
RECONFIGURE
GO
sp_configure 'show advanced options', 0;
GO
RECONFIGURE
GO
The last step of DAC is connection itself. You have to specify word "ADMIN:" before the server name:

You can have ONLY ONE Dedicated Admin Connection per server at any given moment.
That means: do not forget to close your connection after the exercise and leave ability to connect to your server open at any moment in the future. Learn to do the same in production too.
Faced the problem that I can not actually do it. After a short research found very easy solution.
1. Run SQL Server Configuration Manager. You can use an icon from windows menu or if it is not available you might use the following (or modified for your system/version) command:
C:\Windows\SysWOW64\mmc.exe /32 C:\Windows\SysWOW64\SQLServerManager12.msc
2. In Configuration Manager locate your SQL Server instance and choose properties by right click on it.
3. In Properties, choose "Startup Parameters" tab:
4. In the box specify a trace flag: "-T7806" and press Add.
5. Then hit OK and restart SQL Server Service.
Another way to do the same thing is would be editing Windows registry by RegEdit.exe
You just have to add new key "SQLArgX" with "-T7806" in
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQLServer\Parameters
That should look something like this:
That also require SQL Server instance restart.
Also, in order to be able to establish DAC you have to enable it within your SQL Server configuration:
sp_configure 'show advanced options', 1;
GO
RECONFIGURE
GO
sp_configure 'remote admin connections', 1;
GO
RECONFIGURE
GO
sp_configure 'show advanced options', 0;
GO
RECONFIGURE
GO
The last step of DAC is connection itself. You have to specify word "ADMIN:" before the server name:
You can have ONLY ONE Dedicated Admin Connection per server at any given moment.
That means: do not forget to close your connection after the exercise and leave ability to connect to your server open at any moment in the future. Learn to do the same in production too.
Tuesday, November 18, 2014
How to hide your data within a SQL Server Database
Want to bring your attention to a little and very simple SQL hack.
Do not think anybody can use it in production, but it is still surprisingly interesting and might be dangerous.
At first, will create a table, insert couple of records and verify how it looks:
Both records are visible and available for anybody who has select permission on that new table.

Now will do a trick, add leading zero-character:
Will try to extract data again:
Test is there, you can tell it by data length numbers, but you do not see it:

Only the way to see the text again is to suppress the leading zero-character:
Now you can see the hidden text.

Interesting that despite of leading zero-character we still can use hidden string for executions:
That statement will be successfully executed and return a value

(That might be the dangerous part, when executed invisible statements produce some results)
Do not forget to cleanup after yourself:
Do not think anybody can use it in production, but it is still surprisingly interesting and might be dangerous.
At first, will create a table, insert couple of records and verify how it looks:
| Use TestDB; GO CREATE TABLE tbl_Hidden_Data ( ID INT IDENTITY(1,1), Hidden_Text VARCHAR(100) ); GO INSERT INTO tbl_Hidden_Data(Hidden_Text) VALUES ('My little hidden Secret'), ('SELECT ''Invisible Pink Unicorn is hidden here'' as [Result of Hidden Command]'); GO SELECT * FROM tbl_Hidden_Data; GO |
Both records are visible and available for anybody who has select permission on that new table.
Now will do a trick, add leading zero-character:
| UPDATE tbl_Hidden_Data SET Hidden_Text = CHAR(0) + Hidden_Text; |
Will try to extract data again:
| SELECT * , LEN(Hidden_Text) as Text_Length , DATALENGTH(Hidden_Text) as Text_Size FROM tbl_Hidden_Data; |
Test is there, you can tell it by data length numbers, but you do not see it:
Only the way to see the text again is to suppress the leading zero-character:
| SELECT *, SUBSTRING(Hidden_Text,2,@@TEXTSIZE) as Visible_Text FROM tbl_Hidden_Data; |
Now you can see the hidden text.
Interesting that despite of leading zero-character we still can use hidden string for executions:
| DECLARE @SQL VARCHAR(100); SELECT @SQL = Hidden_Text FROM tbl_Hidden_Data WHERE ID = 2; EXEC (@SQL); |
(That might be the dangerous part, when executed invisible statements produce some results)
Do not forget to cleanup after yourself:
| DROP TABLE tbl_Hidden_Data; |
Tuesday, November 11, 2014
Multipurpose Stored Procedures.
Still under impression of Kimberly L. Tripp session "Dealing with Multipurpose Procs and PSP the RIGHT Way!" on PASS Summit 2014 in Seattle.
It was wonderful session with a simple idea of how to make Multipurpose Stored Procedures work faster. I did a research couple of years ago on similar topic, but I did not come up with such a wonderful idea.
At first, will explain what it is a Multipurpose Stored Procedure.
Look from a developer's perspective: There is a business need to have a search for a client and it has to be universal search by any client's attribute. There can be entered anything: Part of first or last name, part of email address, phone number, account number, part of a street address. There even more intelligent requirement to search not just by one, but also by two, three or more parameters.
How would you implement that?
It would be nice to have a stored procedure which would be called in a way like in example below:

There are several different ways to implement that logic. The most straight way looks like this:
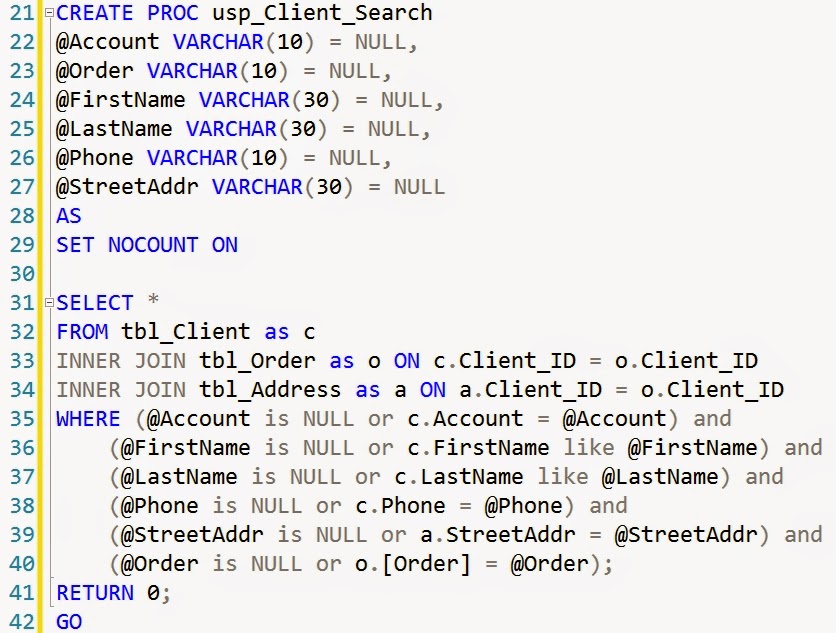
That approach is the easiest one and it is the least optimal.
That might easily happen that generated plan for that query will be horrible for the most of passing to that stored procedure values.
In order to prevent generation of the bad plan you can build the stored procedure with RECOMPILE option, but you also can build a query for an execution within the stored procedure dynamically. That will recompile only that single query, not the whole procedure:


That code with recompilation will work better because there will be no "bad" query generated.
However, that solution still can hit the scalability ceiling. Each run of that stored procedure will still cause plan recompilation and high CPU usage.
Kimberly's idea was that we do not have to recompile ALL plans. For queries where we expect return of single row and which will use an index we can leave the plan in cache.
I think that is a brilliant idea. It will save recompilation CPU time for all requests, which will do index seek and return one or few items.
In my example, these kind of plans will be produced in case we supply @Account, @Order or @Phone variables.
So, here is the changed second part of my stored procedure to demonstrate that idea:

In case of @Account, @Order or @Phone variables "OPTION (RECOMPILE)" won't be added to a query and that query will stay in cache for future usage.
Thanks Kimberly for great idea.
It was wonderful session with a simple idea of how to make Multipurpose Stored Procedures work faster. I did a research couple of years ago on similar topic, but I did not come up with such a wonderful idea.
At first, will explain what it is a Multipurpose Stored Procedure.
Look from a developer's perspective: There is a business need to have a search for a client and it has to be universal search by any client's attribute. There can be entered anything: Part of first or last name, part of email address, phone number, account number, part of a street address. There even more intelligent requirement to search not just by one, but also by two, three or more parameters.
How would you implement that?
It would be nice to have a stored procedure which would be called in a way like in example below:
There are several different ways to implement that logic. The most straight way looks like this:
That approach is the easiest one and it is the least optimal.
That might easily happen that generated plan for that query will be horrible for the most of passing to that stored procedure values.
In order to prevent generation of the bad plan you can build the stored procedure with RECOMPILE option, but you also can build a query for an execution within the stored procedure dynamically. That will recompile only that single query, not the whole procedure:
That code with recompilation will work better because there will be no "bad" query generated.
However, that solution still can hit the scalability ceiling. Each run of that stored procedure will still cause plan recompilation and high CPU usage.
Kimberly's idea was that we do not have to recompile ALL plans. For queries where we expect return of single row and which will use an index we can leave the plan in cache.
I think that is a brilliant idea. It will save recompilation CPU time for all requests, which will do index seek and return one or few items.
In my example, these kind of plans will be produced in case we supply @Account, @Order or @Phone variables.
So, here is the changed second part of my stored procedure to demonstrate that idea:
In case of @Account, @Order or @Phone variables "OPTION (RECOMPILE)" won't be added to a query and that query will stay in cache for future usage.
Thanks Kimberly for great idea.
Sunday, November 9, 2014
Newest SQL Server Feature – “Query Store”
Very important disclosure:
New Functionality description:
Facts:
New Functionality in my own understanding:
I’ve tried to capture as many details as possible and come up with reasonable explanation.
Captured list of new DMVs:
sys.query_store_query_text
sys.query_store_query
sys.query_store_plan
sys.query_store_runtime_stats
* The best guess.
** No clue.
Below is a possible data schema for the new feature:
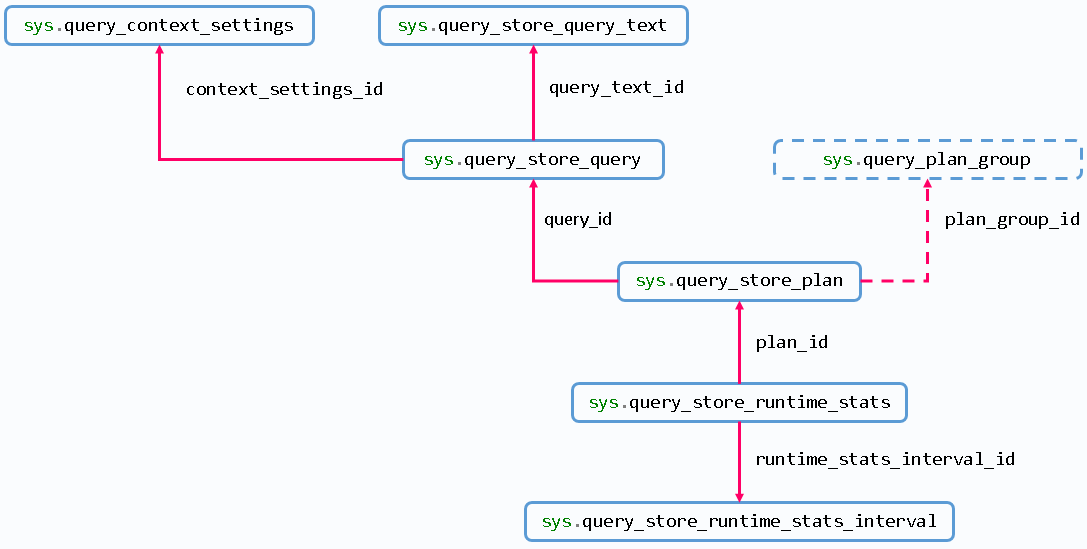
How does it work?
Here are the sample steps of performance troubleshooting in the new environment:
Step #1. Altering database to be covered by Query Store:
Step #5. Mark fastest plan to be used for the query:
That stored procedure will set is_forced_plan = 1 in "sys.query_store_plan" DMV.
For “sp_query_store_force_plan” you have to supply plan_id as a parameter.
(The second parameter is unknown. That can be query_id or context_settings_id)
There can be situations when:
- Do not try described functionality in production. Do not try it in test also. That functionality is not available for the public yet.
- I did not try the new functionality either. That means I might not cover everything and not everything covered is covered precisely.
- Do not build false expectations, some functionality might disappear in a release of the product, but some new functionality might be added.
- Whole blog post is based on a presentation of Microsoft Principal Architect Conor Cunningham on PASS Summit 2014 in Seattle.
- You might be trapped in a situation when SQL queries suddenly start to work slowly. Why that is happen? There are some reasons when your cached plan can be invalidated or just simply pushed out of plan cache because of memory pressure. That would cause query plan recompilation and there is no any guarantee that new plan will be the same as the old good one.
- I've seen that situation a lot for old and current SQL Server versions. These situations are difficult to troubleshoot and getting rid of the bad plan not always possible. Usually, updating statistics is the cure, which caused bad plan invalidation and recompilation to the good one. Since SQL Server 2012, updating statistics causes plan invalidation only if data have significantly changed. That means you have to search for a bad plan and delete it manually. All of that takes time and as I mentioned earlier, there is no guarantee, that newly compiled plan would be the best.
- Didn't you wish to store your “good plans” in cache forever and not allow SQL Server to push them out? Microsoft have heard yours pray and developed “Query Plan Storage”, which will allow you to manage query plans in the way you want.
New Functionality description:
- Store the history of plans for each query;
- Capture runtime statistics of each plan per time unit (default is 1 hour) (Max, Min, Avg, Last, Std dev for duration, IO writes/Reads, CPU waits, memory usage, DOP, rowcount values);
- Compile regular queries with parameters as “auto-parameterized” queries;
- Identify queries that have “gotten slower recently”;
- Allow you to force plans easily;
- Make sure this works across server restarts, upgrades, and query recompiles;
- DBA can determine query retention time for Query Store;
- Establishing base lines for query executions;
- Performance regression testing after server upgrades or migrations;
Facts:
- Query Texts start at the first character of the first token of the statement; end at last character of last token;
- Comments before/after do not count;
- Spaces and comments inside *do* count;
- Statement_sql_handleis MD5 hash of text;
- Context_settingscontains one row per unique combination of plan-affecting settings;
- Different SET options cause multiple “queries” in the Query Store;
- Plan caching/recompilation behavior unaffected;
- Statistics are recorded when query execution ends.
New Functionality in my own understanding:
- Each executed query in your system will not just go to Query Plan Cache, but also will be recorded into Query Store;
- Along with a query, runtime execution parameters, such as duration, IO, CPU etc. also will be recorded;
- Query Store will permanently save all plans and stats, which will be available even after server reboot. That means lower time for plan recompilations on busy servers.
- Plans will be available even after server migration. That means you cannot just reuse “old good plans”, but also compare performance change on the new hardware for individual queries.
- Query Store might contain more than one plan for a single query;
- DBA will be able to mark a single the best plan for a particular query to be chosen by SQL engine for execution;
- Privileges to mark a plan for execution will be available for an Admin role ONLY;
- New functionality might be available initially in SQL Azure and then implemented in the next version of SQL Server. Currently that functionality is available for SQL Server engine version 13.0.11.152.
I’ve tried to capture as many details as possible and come up with reasonable explanation.
Captured list of new DMVs:
- sys.query_store_query_text
- sys.query_store_query
- sys.query_store_plan
- sys.query_store_runtime_stats
- sys.query_store_runtime_stats_interval
- sys.query_context_settings
sys.query_store_query_text
| Column name | Type | Description |
|---|---|---|
| query_id | bigint* | ID of the query text. This is unique value within a (server or database)* |
| query_sql_text | nvarchar(max) | Text of the SQL query. |
| statement_sql_handle | varbinary(64) | A token that refers to the statement that the query is part of. MD5 hash to text. |
| More columns are available | ||
sys.query_store_query
| Column name | Type | Description |
|---|---|---|
| query_id | bigint* | ID of the query. This is unique value within a (server or database)* |
| query_text_id | bigint* | ID of the query text. This is the same value as the query_text_id in the sys.query_store_query_text catalog view. |
| context_settings_id | bigint* | ID of the query context settings. This is the same value as the context_setting_id in the sys.query_context_setting catalog view. (Refers to context settings such as “quoted identifiers” etc.)* |
| object_id | int | ID of the object (for example, stored procedure or user-defined function) for this query plan. For ad hoc and prepared batches, this column is zero. |
| batch_sql_handle | varbinary (64) | A token that refers to the batch that the query is part of. For ad hoc and prepared batches, this column is null. Column is nullable. |
| query_hash | binary(8) | Binary hash value calculated on the query and used to identify queries with similar logic. You can use the query hash to determine the aggregate resource usage for queries that differ only by literal values. |
| is_internal_query | bit* | (Is query Distributed, Replicated, etc.?)** |
| query_parameterization_type | smallint* | Query parameterization type. For queries without parameters, this column is zero. |
| query_parameterization_type_desc | nvarchar (60)* | Description of query parameterization type. 0 = None 1 = User |
| initial_compile_start_time | datetime3 | Date and Time when query was initially compiled. (Format is datetime2 + time zone shift?)** |
| last_compile_start_time | datetime3 | Date and Time of query’s last compilation. For query which had no recompilation that parameter is (equals to initial_compile_start_time or NULL)** |
| More columns are available | ||
sys.query_store_plan
| Column name | Type | Description |
|---|---|---|
| plan_id | bigint* | ID of the plan. This is unique value within a (server)* |
| query_id | bigint* | ID of the query. This is the same value as the query_id in the sys.query_store_query catalog view. |
| plan_group_id | int | ID of the query plan group. This is the same value as the plan_group_id in the sys.query_plan_group catalog view.** |
| engine_version | nvarchar (128) | Version of the instance of SQL Server plan has been compiled, in the form of 'major.minor.build.revision'. |
| query_plan_hash | binary(8) | Binary hash value calculated on the query execution plan and used to identify similar query execution plans. You can use query plan hash to find the cumulative cost of queries with similar execution plans. Will always be 0x000 when a natively compiled stored procedure queries a memory-optimized table.* |
| query_plan | nvarchar (max) | Contains the compile-time Showplan representation of the query execution. The Showplan is in text format.* |
| is_parallel_plan | bit* | Indicates whether the plan uses parallelism. 0 = not used 1 = used Column is not nullable.* |
| is_forced_plan | bit* | Indicates whether the plan for particular query is forced to be executed. In case of multiple plans for the same query SQL Engine will execute a plan where that column equals One. (In case all plans have zero, the most recent plan will be executed.) 0 = plan is not forced to be executed 1 = plan is not forced to be executed Column is not nullable.* |
| force_failure_count | int | Counter of cases when is_forced_plan = 1, but by some reason SQL Engine does not use that plan. (f.i. index used by that plan has been modified or deleted and SQL Engine can’t use that plan anymore) * |
| last_force_failure_reason | smallint | Column keeps code of the last force failure reason. In case of force_failure_count = 0 it also will be Zero. Column is not nullable.* |
| last_force_failure_reason_desc | nvarchar (60)* | Description of force failure reason. 0 = none |
| count_compiles | int* | Counter of compiles. Starts from One. Column is not nullable. ** |
| More columns are available | ||
sys.query_store_runtime_stats
| Column name | Type | Description |
|---|---|---|
| runtime_stats_id | bigint* | ID of the runtime plan stats. This is unique value within a (server or database)* |
| plan_id | bigint* | ID of the plan. This is the same value as the plan_id in the sys.query_store_plan catalog view. |
| runtime_stats_interval_id | int | ** |
| execution_type | smallint | Indicates special type of execution of SQL query. For instance parallel plan. For plans without any specialties column equals Zero. Column is not nullable.* |
| execution_type_desc | nvarchar (60)* | Description of query parameterization type. 0 = Regular* |
| first_execution_time | datetime3 | Date and Time when plan first time was executed. (Format is datetime2 + time zone shift?)** |
| More columns are available | ||
** No clue.
Below is a possible data schema for the new feature:
How does it work?
Here are the sample steps of performance troubleshooting in the new environment:
- Alter database to be covered by Query Store;
- Use set of DMV’s to see executed queries and their plans;
- Find the bottleneck;
- Find the fastest plan, which by some reason was replaced by a slow one;
- Mark fastest plan to be used for the query.
Step #1. Altering database to be covered by Query Store:
| ALTER DATABASE MyTestDB
SET QUERY_STORE (interval_length_minutes = 1); ALTER DATABASE MyTestDB SET QUERY_STORE = ON; |
Step #5. Mark fastest plan to be used for the query:
| EXEC sp_query_store_force_plan 1, 1; |
That stored procedure will set is_forced_plan = 1 in "sys.query_store_plan" DMV.
For “sp_query_store_force_plan” you have to supply plan_id as a parameter.
(The second parameter is unknown. That can be query_id or context_settings_id)
There can be situations when:
- You made a wrong choice;
- Forced plan is not the best anymore;
- Some metadata have changed that causes Forced Plan to
fail.
In these cases you can un-force a forced plan by following command:
(I assume that stored procedure is accepting the same parameters as the forcing one).
Afterwords:
In these cases you can un-force a forced plan by following command:
| EXEC sp_query_store_unforce_plan 1, 1; |
(I assume that stored procedure is accepting the same parameters as the forcing one).
Afterwords:
I believe hundreds of thousands
of SQL Servers in the world struggling because of bad execution plans, by some
reason, pushed out good ones.
The new SQL Server “Query Store”
feature will solve that problem and definitely be a very useful tool in hands
of knowledgeable DBAs.
Please fill free to contact me
in case you think I did not understand all new functionalities correctly or by
the time when that feature officially go to a release some will be changed or new
be added.
Subscribe to:
Posts (Atom)