Usually, project managers and lazy team leads make simple decision of using Unicode (NVARCHAR) for SQL Server fields.
As a result, Accounts, Social Security Numbers, and all other 100% non-unicode character fields take double space on disk and in memory. Their arguments are simple: It is easier/faster/cheaper to have all unicodes, than deal with unicode conversion problems.
As a SQL Server consultant, who makes money on performance troubleshooting, I appreciate their intention to make their databases and SQL Server slower. That might be my place of work in the future to make their system more reliable and faster.
However, as Database architect I have to make sure that all columns have appropriate data type and that data type uses minimum storage. For that purpose I have to do conversion of unicode strings to non-unicode.
In this blog post for simplicity I will use SQL server as a data source, but it can be MySQL, Oracle, Text or Excel file or anything else.
Disclaimer:
In my assumption, if you are reading this blog you have pretty good SSIS skills and I do not have to explain how to create a package, data flow task, connection and add script component to your task.
Preparation.
At first, in TestDB database (NON-PRODUCTION) we will create source table "tbl_Test_Unicode", target table "tbl_Test_NonUnicode" and insert some bad data into the source:| USE TestDB GO CREATE TABLE tbl_Test_Unicode(UColumn NVARCHAR(10)); GO CREATE TABLE tbl_Test_NonUnicode(NUColumn VARCHAR(10)); GO INSERT INTO tbl_Test_Unicode(UColumn) SELECT N'ABC' + CAST(0xC296 AS NVARCHAR) + N'DEF'; GO SELECT * FROM tbl_Test_Unicode GO |
As a result of that script we will see following:

Then will create Simple SSIS package with only one data flow task:

Problem 1.
Will create OLE DB Source and OLE DB Destination for tables "tbl_Test_Unicode" and "tbl_Test_NonUnicode":
"Validation error. Data Flow Task 1: Data Flow Task 1: Columns "UColumn" and "NUColumn" cannot convert between unicode and non-unicode string data types."

That was expected and we will easily solve that problem:
Problem 2.
We solve problem #1 in three easy steps:(That method is described in more details by Greg Robidoux in MSSQLTips)
First: Add "Data Conversion" task between Source and Destination:


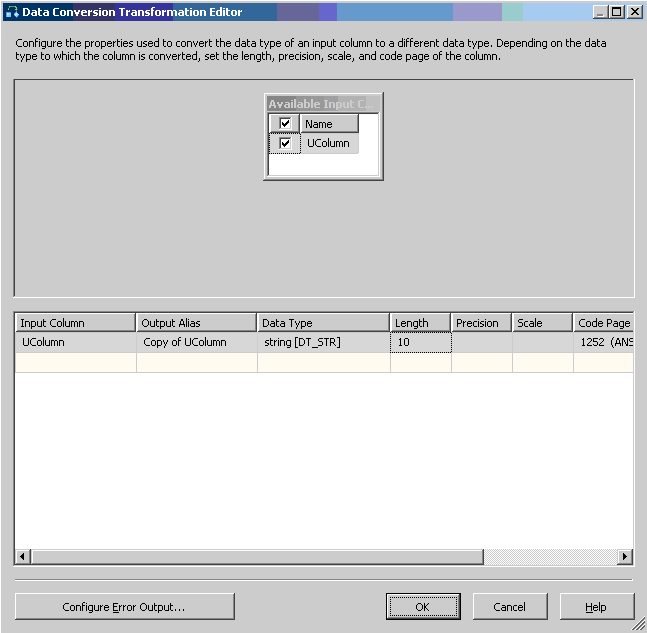
As a third step we open OLE DB destination and redirect new column:

As a result we have data transformation task without any validation errors:

Look at the error:
"[Data Conversion [39]] Error: Data conversion failed while converting column "UColumn" (34) to column "Copy of UColumn" (47). The conversion returned status value 4 and status text "Text was truncated or one or more characters had no match in the target code page."."
SSIS simply can't translate unicode character to the default dataset. That is understandable, but how to get rid of that annoying extra symbol? Why just simply not ignore it?
Problem 3.
Will try to solve problem #1 differently, by adding "Derived Column" task instead of "Data Conversion":
After little adjustments within OLE DB Destination our task has to look like this:

After we try to execute the package we got an error on the conversion step:

Error is little bit different. This time it does not say anything about mismatch, only about truncation:
"[Derived Column [52]] Error: The "component "Derived Column" (52)" failed because truncation occurred, and the truncation row disposition on "output column "Copy of UColumn" (62)" specifies failure on truncation. A truncation error occurred on the specified object of the specified component."
Why it is saying about truncation???
I've tried following code: "(DT_STR,10,1252)SUBSTRING(UColumn,1,4)", which also failed, while "(DT_STR,10,1252)SUBSTRING(UColumn,1,3)" worked perfectly.
That means during "Derived Column" conversion, SSIS can't even correctly recognize the problem.
Solution.
At this point somebody would offer to use a query to convert the data on the source.That totally works with SQL Server, MySQL and Oracle, but if you have Text or Excel file that would be a problem.
Also, somebody can give up and change column's data type in the source to unicode, or just make a trick and use unicode-based staging table for two step conversion.
However, I wouldn't write this blog if I hadn't have a solution.
In my case to solve that problem I've used "Script Component" - one of the the most scariest components in SSIS.
When you place "Script Component" into "Data Flow" task it immediately asked about type of component you want. In our case we need third option: transformation:

Then put new component between source and destination like this:


Then in "Inputs and Outputs" select "Output Columns" and click "Add Column".

After new column is added rename it to "NUColumn", change it's type to "string "DT_STR" and fix string length by making it "10"

After that you are ready for "Script" section specify "Visual Basic" and click Edit Script.
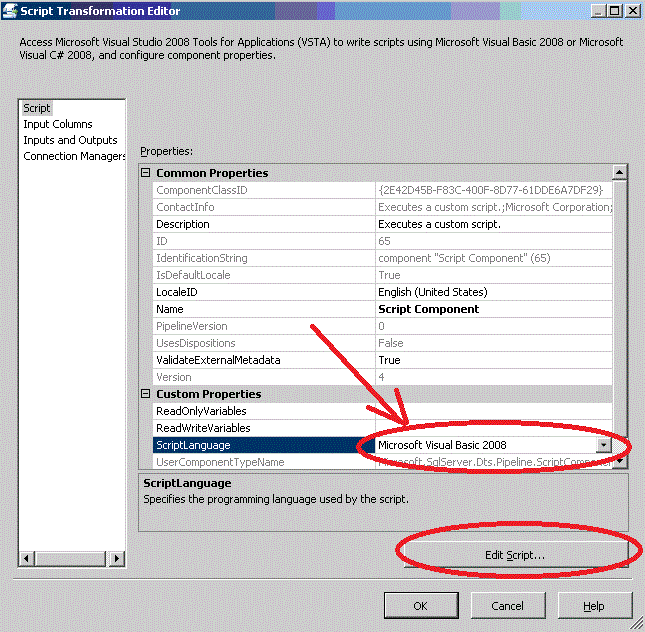
When Visual Studio window will open in a procedure called "Input0_ProcessInputRow" add a line of code: "Row.NUColumn = Row.UColumn.ToString()" like this:

Then close Visual Studio and click OK in "Script Component".
After that "OLE DB Destination" will need some adjustments, but when it is fixed your package should work perfectly:

Package finished without any error, but destination table still has some problems:

The unicode character has been replaced by question mark.
You might be OK with that or you can add one more step to replace it by empty space if you are 100% sure that you do not have question marks in your text.
Anyway, that is not easy, but possible way to get rid of unicode characters in SSIS data source.
My colleagues and I often use the methods in problems 1-3, to varying degrees of success to circumvent conversion issues with data files. I just tested your scripting solution on a real-world client file that had been giving me fits. It worked fantastically. Thanks for the post.
ReplyDeleteSlava, this post saved the day for us. We need to eventually change our schema to support nvarchar but being able to fix the immediate problem quickly buys us time to that work the right way.
ReplyDeleteIf this is a data warehouse project, identical data type should be designed in the staging area which means the same nvarchar in the destination table. No derived, conversion or script is needed.
ReplyDeleteTSQL in sp between staging and production area will convert from nvarchar to varchar implicitly without using any data conversion function such as cast or convert and replace unicode value with a space or ? (I forgot). Most like a ?.
A data model design change in destination can solve this kind of issues and leverage mapping between source and destination automatically with the same data type and column name.
Thank you for your post - this came in handy today. I couldn't convert to nvarchar, and didn't want to discard the data...thanks again!
ReplyDeleteThank you so much! Simple solution that solves a "complex" problem!
ReplyDeleteThank you very much!
ReplyDeleteThank you ... excelent...!!!
ReplyDelete